 Octets courts: Le robot d'exploration Web est un programme qui parcourt Internet (World Wide Web) d'une manière prédéterminée, configurable et automatisée et effectue une action donnée sur le contenu analysé. Les moteurs de recherche comme Google et Yahoo utilisent l'araignée comme moyen de fournir des données à jour.
Octets courts: Le robot d'exploration Web est un programme qui parcourt Internet (World Wide Web) d'une manière prédéterminée, configurable et automatisée et effectue une action donnée sur le contenu analysé. Les moteurs de recherche comme Google et Yahoo utilisent l'araignée comme moyen de fournir des données à jour.
Webhose.io, une entreprise qui fournit un accès direct aux données en direct de centaines de milliers de forums, d'actualités et de blogs, a publié le 12 août 2015 les articles décrivant un petit robot d'exploration Web multithread écrit en python. Ce robot d'exploration de sites Web python est capable d'explorer l'ensemble du Web pour vous. Ran Geva, l'auteur de ce petit robot d'exploration en python, dit que:
J'ai écrit comme «Sale», «Iffy», «Bad», «Not very good». Je dis qu'il fait le travail et télécharge des milliers de pages à partir de plusieurs pages en quelques heures. Aucune configuration n'est requise, aucune importation externe, exécutez simplement le code Python suivant avec un site de départ et asseyez-vous (ou allez faire autre chose car cela pourrait prendre quelques heures, voire quelques jours selon la quantité de données dont vous avez besoin).Le robot d'exploration multi-thread basé sur python est assez simple et très rapide. Il est capable de détecter et d'éliminer les liens en double et d'enregistrer à la fois la source et le lien qui peuvent ensuite être utilisés pour trouver des liens entrants et sortants pour le calcul du classement de page. C'est totalement gratuit et le code est listé ci-dessous:
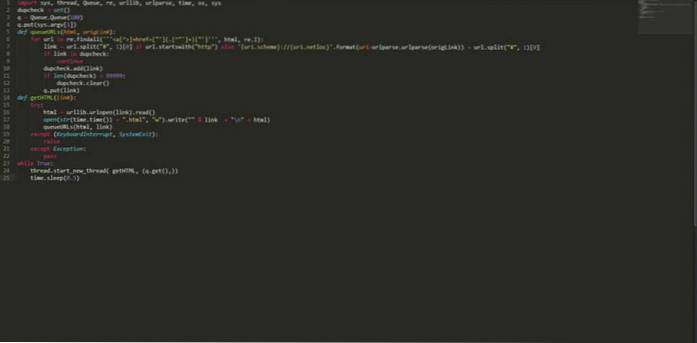
import sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): pour l'url dans re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): link = url.split ("#", 1) [0] si url.startswith ( "http") else 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] si lien dans dupcheck : continuez dupcheck.add (lien) si len (dupcheck)> 99999: dupcheck.clear () q.put (lien) def getHTML (lien): essayez: html = urllib.urlopen (lien) .read () open (str (time.time ()) + ".html", "w"). write (""% link + "\ n" + html) queueURLs (html, lien) sauf (KeyboardInterrupt, SystemExit): augmenter sauf Exception: passer tandis que True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0.5) Enregistrez le code ci-dessus avec un nom, disons "myPythonCrawler.py". Pour commencer à explorer n'importe quel site Web, tapez simplement:
$ python myPythonCrawler.py https://fossbytes.com
Asseyez-vous et profitez de ce robot d'exploration Web en python. Il téléchargera l'intégralité du site pour vous.
Devenez un pro de Python avec ces cours
Aimez-vous ce robot d'exploration Web multi-thread basé sur python simple et mortel? Faites-nous savoir dans les commentaires.
Lire aussi: Comment créer une clé USB amorçable sans aucun logiciel sous Windows 10